코드스쿼드에서 한 달간 진행하던 프로젝트가 끝났습니다. 끝난 기념으로 회고를 작성해봅니다..(기술을 곁들인) 처음 진행하는 팀 프로젝트라 걱정도 되었지만 정신없이 만들다보니 4주가 어떻게 흘러갔는지 모르겠습니다. 4주라는 시간의 제약 때문에 처음 프로젝트를 시작할 때부터 모든 것을 만들지 못한다는 것은 알고있었지만 막상 끝난다고 생각하니 아쉬운 생각이 많이 듭니다. 가장 부족하게 느꼈던 부분은 기능 구현에 우선 순위가 밀려 실행하지 못했던 것들입니다. 서비스를 개발하는데 있어서 돌아가는 코드가 가장 중요하기에 우선 순위가 밀렸다고는 하지만 개인적으로 아주 중요하게 생각하는 부분이기에 더욱 아쉽습니다.
[1주차] - 그라운드 룰 정하기, API, ERD, UML 다이어그램 작성
첫 주에는 Ground Rule과 협업 규칙을 정하는 것으로 시작했습니다. 애자일하게 일하고자 Daily Scrum을 매일 아침 10시에 30분간 진행했습니다. 제이든이 스크럼 마스터를 자청하여 4주간 진행해주셨는데 감사했습니다. 사실 이 전까지 코드스쿼드에서도 스크럼을 해왔지만 어느정도 서로의 안부를 묻는 형식적인 규약에 지나지 않았는데, 팀 프로젝트를 진행할 때 스크럼을 통해서 iOS, 프론트가 어떤 일들을 하고있는지 대략적으로 알 수 있게 된 것이 정말로 큰 도움이 되었다고 생각합니다. 조원들의 컨디션과 진행 상황에 따라서 백엔드에서 할 일의 우선순위를 조정하면서 유기적으로 일할 수 있었습니다.
첫 주 가장 공을 들였던 부분은 API의 명세를 확정하는 것이었습니다. 이번 프로젝트는 프론트뿐만 아니라 iOS와도 협업을 해야했는데, 걱정했던 부분은 프론트와 iOS의 요구사항이 미세하게 다르다는 점이었습니다. 예를 들면, 프론트에서는 이슈 필터 기능만 요구사항에 있지만, iOS에서는 검색 기능이 같이 필요하고, 프론트에서는 라벨의 글자 색상을 밝은 색, 어두운 색을 고를 수 있었지만 iOS에서는 배경 색에 따라 자동으로 글자 색이 정해지는 요구사항이 있었습니다. 이렇게 iOS와 프론트 두가지 클라이언트 측 요구사항에 맞게 API를 구성해야했습니다.
현업에서는 이러한 부분들이 훨씬 두드러질 것이라고 생각됩니다. 실제로 웹에서 제공하는 기능과 어플에서 제공하는 기능 자체가 상이한 경우도 제가 서비스를 사용하는 소비자로서도 많이 느꼈던 부분이라고 생각합니다. 코드스쿼드에서도 이런 부분으로 많은 논의가 있었는데요, 모바일 앱과 웹은 요구사항이 점점 틀어질 수 밖에 없기 때문에 처음부터 API를 분리해서 설계하는 의견도 있었고, API는 최대한 공통적인 데이터를 제공하고 각 클라이언트에서 다르게 요구사항을 만족시켜주도록 설계하는 의견도 있었습니다. 저도 마찬가지로 고민을 했는데, 아래 영상을 보고 Rest API에 가깝게 API를 작성한다고 했을 때, 후자가 좀 더 Uniform Interface에 가깝다는 생각이 들어 공통의 API를 구성하고자 했습니다.
그리고 요구사항이라는 것은 항상 모호한 점이 있기 때문에 팀원마다 요구사항을 다르게 이해하기도 했습니다. 백엔드에서 생각하는 요구사항과 클라이언트 측에서 이해한 요구사항이 달랐기 때문에, API 명세를 확정하는 회의에서 세부 기능을 다함께 살펴보면서 손발을 맞추는데 많은 시간을 쏟았습니다.
https://deview.kr/2017/schedule/212
그런 REST API로 괜찮은가
발표자 : 이응준
deview.kr
[2주차] - API 구현(이슈 목록 조회, 이슈 상세 조회 기능)
2주차에는 기능 구현을 시작했습니다. 좋았던 점은 1주차에 API를 세세하게 논의해서 정해두니 API가 수정되는 경우가 많이 없었다는 점입니다. 코드의 양이 점점 많아졌을 때 간단한 명세 변경만으로도 프로젝트에 미치는 영향이 크게 다가왔는데, 처음에 상세하게 결정을 해두니 변경할 일이 많이 없어서 다른 팀들에 비해서 혼란을 적게 겪었습니다. 그렇지만 사실 프로젝트의 규모가 더 커지면 명세를 상세하게 결정하는 것으로는 분명 한계가 있으므로 유연한 설계를 통해서 변경에 열려있는 구조를 만드는 것이 제일 중요해보입니다.
반대로 API를 세세하게 설계했지만, API를 RESTful하게 작성하지 못해 아쉽기도 했습니다. 예를 들면, 이슈 목록을 조회할 때 /api/issues에 GET 요청을 보내면 이슈 목록뿐만 아니라 열린 마일스톤 개수, 닫힌 마일스톤 개수 등을 함께 가져오는데 이는 resource에 따른 구분에 어긋난다고 생각되었습니다. 하나의 API가 하는 일이 많다보니 DTO에 많은 정보를 담아야하고, DTO를 조립하는 로직도 복잡해졌습니다. DTO가 커지다보니 사소한 변경에 따라 수정해야하는 범위도 넓어져 불편함이 있었습니다. milestone과 필터 정보와 관련된 API는 별도 API 요청으로 분리했으면 훨씬 좋은 구조였을 것 같아 아쉬웠습니다.
어려웠던 점은 첫째로, Spring Jdbc 혹은 Jdbc Template이 아닌 처음으로 ORM을 사용해보게 되었는데 기존의 사용했던 JDBC에 비해서 추상화 레벨이 높아서 어려움을 많이 겪었습니다. 원하는대로 객체가 Mapping되지 않았고, 결국 이는 제가 구체적으로 객체가 Mapping되는 원리를 모르기 때문이었습니다. 공식 문서 및 여러 자료를 참조하여 문제들을 해결할 수 있었습니다.
둘째로 이슈 목록 조회 기능 구현에서 DB 관점에서 많은 고민을 할 수 있었습니다. 조회 기능은 필터, 페이지네이션, 검색기능을 같이 구현해야했는데 동적인 쿼리 생성이 필요해 Mybatis를 통해 동적 쿼리를 생성해야했습니다. 구현 자체는 그렇게 복잡하지 않았지만 어떻게 쿼리를 날려야 유지 보수가 쉬우면서도 DB에 효율적인 구조를 만들 수 있을지가 고민이었습니다. 구현이 쉬운 방식은 ORM으로 이슈 ID의 목록을 조회하고 각 이슈에 대해 추가로 필요한 정보를 추가 n개의 쿼리를 보내는 방법이었습니다. 그렇지만 n+1 쿼리가 발생하기 때문에 규모가 커지면 굉장히 효율이 떨어지는 방법이라는 생각이 들어 적은 회수의 쿼리로 가져오는 방법을 고민했습니다. 특정 페이지 목록을 불러올 때 특정 페이지에 있는 이슈의 id들을 조회한 후, 각 id에 대해서 필요한 정보(assignee, label, milestone) 등을 Join해서 가져오는 방법으로 2번의 쿼리로 데이터를 가져오는 방법으로 구현했고, 어느정도 코드의 복잡도는 증가했지만 API를 잘 설계했더라면 훨씬 깔끔한 코드로 구현할 수 있었던 부분이라 아쉬웠습니다.
[3주차] - 라벨, 마일스톤 CRUD API 구현, 수동 배포 인프라 구축, CORS 설정
3주차에는 남은 라벨, 마일스톤, 이슈 상세페이지 등 잔여 API 명세를 마무리했습니다. 인프라 구조에도 변경 사항이 발생했는데, 2주차까지는 EC2 한 대에 WAS와 웹 서버 역할을 수행하고, RDS만 별도로 사용하였습니다. 그러나, EC2 하나로는 성능적으로 너무 부족했기에, 3주차에는 EC2를 2대로 확장하여 웹서버, WAS를 분리하였습니다. 배포 측면에서도 두 대 이상의 EC2를 사용하니 별도의 EC2에 각각 관리할 수 있다는 의외의 장점도 있었습니다. 그리고 2주차까지는 애자일하지 못하게도 웹서버, WAS 서버를 각각 배포하여 각각 테스트하였는데 3주차에는 EC2에 각각 배포하여 CORS와 연동을 확인했습니다.
[4주차] - OAuth Github 인증, Github Actions와 AWS CodeDeploy를 통한 CI/CD 구축
마지막 주차에는 다소 늦긴 했지만 CI/CD 환경을 구축했습니다. Github Actions를 통해서 release branch에 merge되거나 push될 때 CI 단계인 테스트, 빌드를 수행하도록 하였으며, 빌드 결과물을 AWS S3에 업로드하고, CodeDeploy는 S3에서 다운받아 압축 해제 후 스크립트를 실행시켜 배포를 진행했습니다. 최종적인 인프라와 CI/CD 흐름도는 아래와 같습니다.
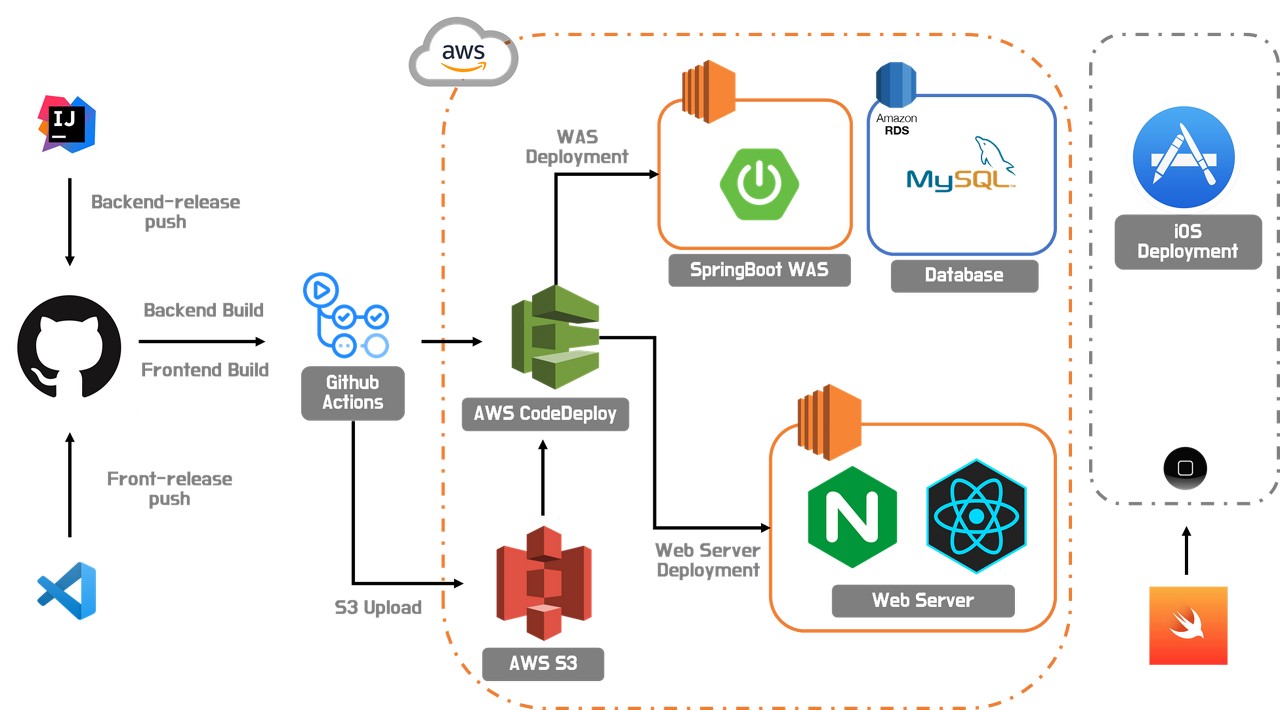
또한 마지막까지 미뤄두었던 OAuth를 적용해보았습니다. OAuth의 대략적인 프로토콜 흐름은 아래와 같이 단순합니다.

그렇지만 본 프로젝트에서는 iOS와 웹서버 모두에게 OAuth 인증 기능을 구현해야했기에 구현 방식이 조금 더 복잡했습니다. 웹서버로 Authorization Grant의 정보를 Github에서 리다이렉트하도록 설정하면, iOS서버가 웹 서버에 의존해야한다는 문제가 있었습니다. 이를 해결하기 위해 WAS로 리다이렉트 한 후, Grant 정보를 클라이언트의 정보에 따라 웹서버 혹은 iOS 서버로 push해주는 방식, 혹은 Github의 OAuth Application을 분리해서 웹과 iOS 각각 다른 redirect url를 설정하는 방법을 고려했습니다. 결국 iOS는 실제 앱스토어 런칭을 하지 않았기 때문에 OAuth를 완성시키지는 못했으나, 아마 iOS와 차후에 프로젝트를 진행하게된다면 후자의 방법을 고려하지 않을까 싶습니다.
4주차 마지막에는 프로젝트를 마무리하는 데모데이가 있었습니다. 마지막 날까지 저는 OAuth를 붙잡고 있었고 팀원들도 잔여 API 명세를 구현하느라 바빴습니다. 그렇지만 데모 직전까지 거의 모든 요구사항을 만족시키고 배포에 성공하니 정말 뿌듯했습니다. 끝난 기념으로 만든 서비스에 롤링 페이퍼도 작성했습니다.

기능 데모
로그인
메인 및 이슈 생성 페이지
이슈 상세 페이지
레이블 및 마일스톤 페이지
Follow-up
프로젝트는 성공적으로 마무리했지만, 개인적으로 아쉬웠던 점이 있어서 추가로 몇 가지 더 진행해보았습니다. 백엔드 개발자로서는 결국 서비스를 만들었을 때 얼마나 효율적으로 동작하고, 높은 트래픽에 잘 견디는지가 중요하다고 생각하는데, 웹서버, WAS는 각각 1대씩 현재 2대를 가용하고 있지만 DB는 단 하나의 RDS만을 사용하기 때문에 그러한 측면에서 DB에 많은 데이터를 bulk insert했을 때 성능이 잘 나오는지를 확인해보고 싶었습니다. 그래서 1차적으로 bulk insert를 통한 select, insert 등 쿼리 성능 수준을 확인하고 이를 대비해서 DB 스키마를 변경하는 것입니다.

1. Vertical Partitioning 적용하기
1.1 현상
위 ERD에서 이슈 목록을 조회할 때 이슈 테이블에서 content를 제외한 컬럼의 데이터를 가져오는데, MySql은 테이블 데이터를 메모리에 로드한 후 특정 컬럼의 데이터만 가져오는 방식으로 동작하기 때문에 content를 불러올 필요가 없는 이슈 목록 조회 시에도 데이터의 사이즈가 큰 content를 메모리에 로드하게 됩니다.
1.2 시도
이를 해결하기 위해 DB 테이블의 Vertical Partitioning을 통해서 Content를 별도 테이블로 분리하여 불필요한 I/O가 발생하지 않도록 개선하는 것을 시도했습니다.
1.3 결과
버티컬 파티셔닝을 적용했는데 큰 차이가 없었습니다. 추정되는 이유는 10만건의 Content가 4천자로 유의차를 발생시킬만큼 크지 않기 때문이라고 생각합니다. 10만단위의 데이터에서는 쿼리 최적화를 먼저 수행하는 것이 가장 효과가 좋다는 결론을 얻었습니다.
2. Sharding, Replication
가장 많은 데이터가 쌓이는 issue 테이블에서 단일 테이블만을 사용하면 많은 데이터가 생성되었을 때 DB의 B+tree 자료구조가 방대해지므로 조회 성능, 그리고 인덱스 갱신에 따른 삽입/삭제/업데이트 성능이 떨어질 수 있습니다.
Horizontal Partitioning 혹은 Sharding을 통해서 별도 테이블로 분리하면 데이터 규모와 상관없이 조회 성능을 어느정도 균일하게 유지할 수 있습니다.
단일 DB만을 사용하면 DB의 성능이 떨어질 뿐만아니라, DB에 장애가 발생했을 때, 혹은 데이터 손실이 발생했을 때 복구할 수 있는 방법이 없다는 점입니다. 가장 간단한 방법은 RDS와 S3를 연동하여 주기적으로 DB 백업을 실행하고, 장애가 발생했을 때 S3의 백업데이터로 롤백을 실행하는 방법입니다만, 데이터 손실이 발생할 수 있습니다. 결론적으로 검토하고 있는 방안 Replication을 통해서 데이터 read에 대한 부하를 분산시키고, write를 했을 때 변경사항을 공유함으로써 DB에 장애가 발생해도 replica DB로 대체하여 즉각적인 복구를 할 수 있게 됩니다.
그렇지만 3번에서 기술하는 이유로 인해 위 방법은 시도하지 않았습니다.
3. JMeter 부하테스트, CloudWatch 모니터링, Covering Index
1번의 Vertical Partitioning을 적용해보았을 때 큰 효과가 없어, 효과가 있다고 알려진 방법을 무작정 도입하는 것보다, 현상을 정확하게 파악하고 그에 맞는 솔루션을 우선적으로 적용하는게 효과가 훨씬 좋을 것 같다는 결론을 내렸습니다. 즉, 데이터를 기반으로 한 엔지니어링을 해야하는 것입니다. 그래서 현상을 좀 더 정확하게 파악하기 위해, 느리다면 구체적으로 DB인지 WAS인지 확인한 후, 어떤 쿼리에서 병목이 발생하는지, 그리고 어느정도 부하가 발생했을 때 느려지는지를 파악하기 위해서 테스트를 진행했습니다. JMeter와 CloudWatch 등 모니터링 툴을 사용했으며, 테스트에 관련된 내용은 아래 포스팅에 정리했습니다. 결론적으로 인덱싱만으로 성능의 유의미한 향상을 얻을 수 있어 이번 프로젝트에 대해서 여기까지 진행하는 것으로 마무리했습니다.
MySQL 쿼리 최적화 - Covering Index
https://porolog.tistory.com/54 슬로우 쿼리 모니터링 - AWS CloudWatch https://porolog.tistory.com/53 DB Bulk Insert, Jmeter 부하테스트 안녕하세요, 오늘은 Issue Tracker 프로젝트를 진행하면서 10만건 이상의 데이터에서
porolog.tistory.com
DB Bulk Insert, Jmeter 부하테스트
안녕하세요, 오늘은 Issue Tracker 프로젝트를 진행하면서 10만건 이상의 데이터에서 비정상적으로 느린 API 응답을 어떻게 개선했는지 기록을 공유하고자 포스팅을 작성합니다. Spring Data JDBC로 Bulk I
porolog.tistory.com
슬로우 쿼리 모니터링 - AWS CloudWatch
https://porolog.tistory.com/53 DB Bulk Insert, Jmeter 부하테스트 안녕하세요, 오늘은 Issue Tracker 프로젝트를 진행하면서 10만건 이상의 데이터에서 비정상적으로 느린 API 응답을 어떻게 개선했는지 기록을
porolog.tistory.com
프로젝트의 깃헙 주소입니다.
https://github.com/codesquad-members-2023-team2/issue-tracker
GitHub - codesquad-members-2023-team2/issue-tracker: 그룹 프로젝트 #1 - IssueTracker team 02
그룹 프로젝트 #1 - IssueTracker team 02. Contribute to codesquad-members-2023-team2/issue-tracker development by creating an account on GitHub.
github.com
'회고' 카테고리의 다른 글
| 코드스쿼드 CS16 과정 중간 회고 (3) | 2023.03.06 |
|---|---|
| 42서울(42Seoul) 라피신 후기 (3) | 2023.01.08 |
| 2022년을 마무리하면서 (4) | 2023.01.01 |


