https://porolog.tistory.com/54
슬로우 쿼리 모니터링 - AWS CloudWatch
https://porolog.tistory.com/53 DB Bulk Insert, Jmeter 부하테스트 안녕하세요, 오늘은 Issue Tracker 프로젝트를 진행하면서 10만건 이상의 데이터에서 비정상적으로 느린 API 응답을 어떻게 개선했는지 기록을
porolog.tistory.com
슬로우 쿼리 개선하기
이전 포스팅에서 슬로우 쿼리를 AWS CloudWatch를 통해서 로깅하도록 설정해보았습니다. 이번에는 로그된 슬로우 쿼리를 확인하고 개선해보겠습니다.
저번 포스팅의 로깅을 통해서 슬로우 쿼리를 찾았습니다. 놀랐던 점은 저는 당연히 아래 쿼리의 페이지네이션, 필터로 이슈 목록을 조회하는 쿼리가 가장 느린 쿼리일 것이라 생각했습니다.
SELECT i.id AS issueId, i.title AS title, u.login_id AS userName,
u.profile_url AS profileUrl, i.opened AS opened, i.created_at AS createdAt, i.closed_at AS closedAt
, m.name AS milestoneName, l.id AS labelId, l.name AS labelName, l.background_color AS backgroundColor, l.font_color AS fontColor
FROM subissue i
LEFT OUTER JOIN issue_label il ON i.id = il.issue_id
LEFT OUTER JOIN label l ON l.id = il.label_id
LEFT OUTER JOIN assignee a ON a.issue_id = i.id
JOIN user u ON u.id = i.user_id
LEFT OUTER JOIN milestone m ON m.id = i.milestone_id
WHERE i.id IN
<foreach item="item" collection="filteredIssueIdList" open="(" separator="," close=")">
#{item}
</foreach>
ORDER BY i.id DESC
그렇지만 로그된 결과를 확인해보니 예상과는 전혀 다르게 아래의 count 쿼리가 7초가 걸리는 슬로우 쿼리였습니다.
SELECT count(id) FROM issue WHERE deleted_at IS NULL AND opened IS TRUE
deleted_at과 opened에 대한 인덱스가 안걸려있기 때문에 Full scan으로 동작해서 쿼리 성능이 떨어졌던 것이었습니다.
개선 전/후의 결과만 먼저 살펴보겠습니다.
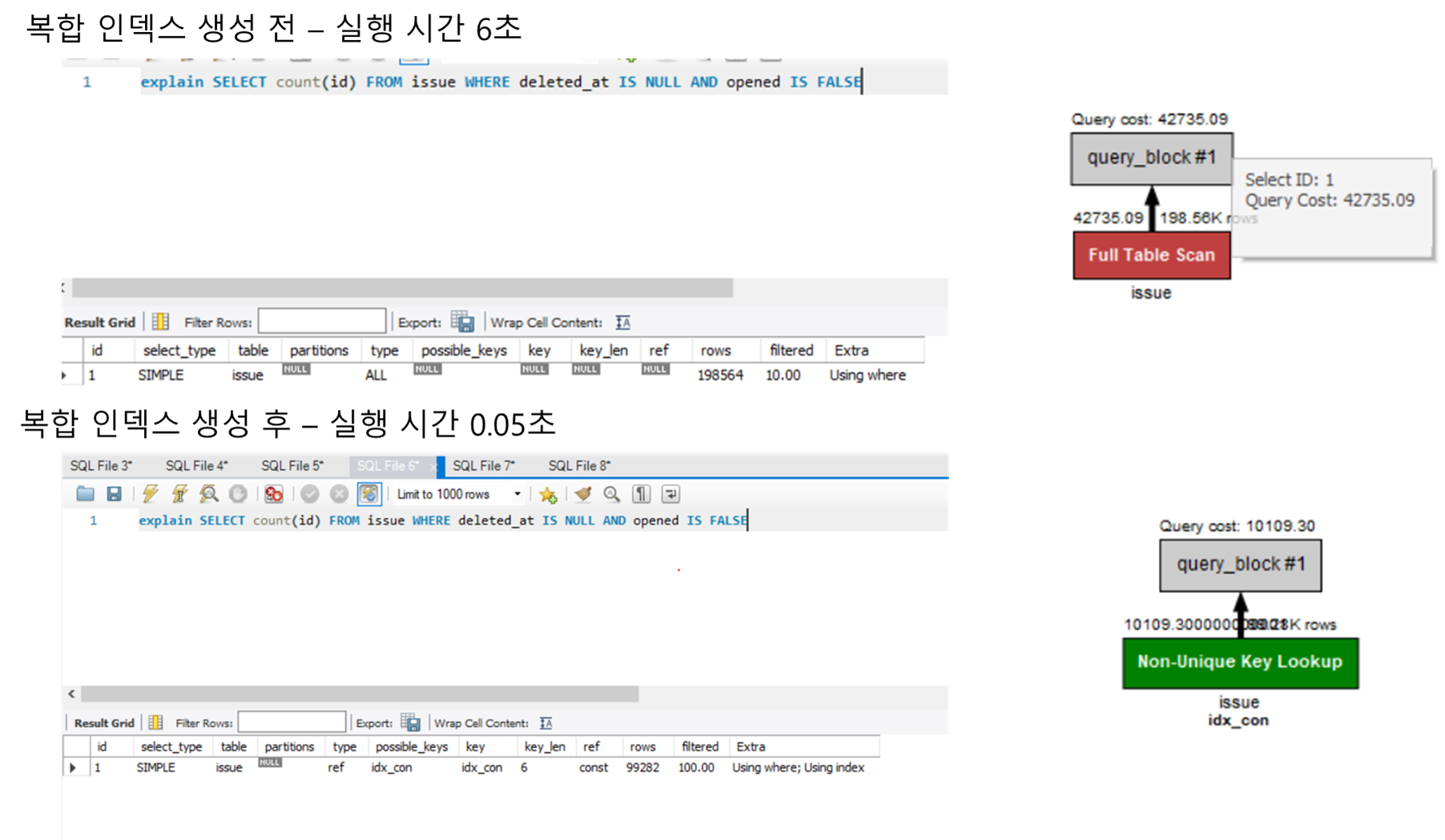
개선 후에는 복합 인덱스를 적용했을 때는 단일 쿼리 기준 0.05초만에 쿼리가 실행되었으며, JMeter로 부하 테스트를 진행했을 때는 200개의 GET 요청이 평균 5초안에 전부 처리될 수 있을정도로 병목을 개선할 수 있었습니다. (아직도 5초가 걸리는 이유는 다른 쿼리는 최적화를 못했기 때문으로 생각됩니다..)

맨 처음에는 deleted_at과 opened를 단일 인덱스로 생성해주었습니다. 이 때, 평균적으로 처리속도가 빨라지긴 했으나 여전히 3~5초정도로 느린 수준이었습니다. 여전히 느릴 수 밖에 없는 것이 soft delete를 나타내는 deleted_at과 이슈 open/close 여부를 나타내는 opened 칼럼이 분산성이 좋지 않다는 것입니다. 삭제 시간을 나타내는 칼럼은 현재는 대부분이 삭제가 안되어있으며, open/close는 이슈라는 현재는 대부분이 open이고, 도메인 특성 상 시간이 지나면 close가 훨씬 많아질 수 밖에 없는 구조이므로 결국 선택도 측면에서는 인덱스가 유의미한 영향을 끼치기 어렵다고 생각했습니다. 실제로, 단일 인덱스를 사용했을 때는 Full scan과 큰 차이가 발생하지 않았습니다.
그렇지만 복합 인덱스를 적용했을 때는 단일 쿼리 기준 0.05초만에 쿼리가 실행되었으며, 서버관점에서는 200개의 GET 요청이 평균 5초안에 전부 처리될 수 있을정도로 병목을 개선할 수 있었습니다. (아직도 5초가 걸리는 이유는 다른 쿼리는 최적화를 못했기 때문으로 생각됩니다..)
선택도가 낮음에도 복합 인덱스를 적용했을 때 빠르게 쿼리가 실행되는 이유가 무엇일까요? 바로 Covering Index에 있었습니다. 위의 쿼리 플랜을 자세히 보면 Extra에 Using index가 있습니다. 이는 Covering Index로 쿼리가 처리됨을 의미합니다.
Covering Index
인덱스는 데이터를 효율적으로 탐색하는 방법입니다. 사전의 index와 거의 동일한 개념입니다. 커버링 인덱스는 쿼리를 충족시키기 위해 필요한 모든 데이터를 갖는 인덱스를 의미합니다. 생성한 인덱스가 필요한 모든 데이터를 가지고 있으면 실제 데이터에 접근할 필요가 없으므로, 조회 성능을 상당히 높일 수 있습니다.
Mysql의 Non Clustered Index와 Clustered Index의 개념을 알고 있다면 아래 그림을 쉽게 이해할 수 있을 것입니다. 인덱스를 추가로 생성하면 Non Clustered Index가 생성되며, 이는 인덱스 컬럼에 대해서 정렬되어있으며, 리프 노드에는 Clustered Index의 값(즉, PK)을 저장하고 있습니다. 따라서 제가 (deleted_at, opened)로 인덱스로 생성한다면, Non Clustered Index이며 두 값에 대해서 정렬되어있으며 노드의 값에 PK가 저장되어있는 것입니다.
여기에서 만약 테이블의 다른 컬럼에 대한 추가 정보가 필요하다면, Clustered Key를 다시 참조하여 Clustered Index 리프 노드에서 실제 테이블의 위치를 찾아 다른 컬럼의 데이터를 읽어오는 작업을 수행하게 됩니다. 그렇지만 커버링 인덱스인 경우 이 실제 데이터 접근 단계를 생략할 수 있으므로 굉장히 빨라지는 것입니다.

Covering Index를 활용했는지는 쿼리 플랜에서 extra 항목을 확인하면 됩니다. Extra의 필드는 아래와 같다고 합니다.
Extra 항목
- Distinct: 중복을 제거하는 경우
- Using where: WHERE로 필터링한 경우
- Using temporary: 데이터 중간 결과를 위해 임시 테이블을 생성한 경우 (보통 DISTINCT / GROUP BY / ORDER BY가 포함되면 임시 테이블 생성)
- Using index: 커버링 인덱스를 사용한 경우
- Using filesort: 데이터를 정렬한 경우
'Computer Science > DB' 카테고리의 다른 글
| Elasticsearch 한국어 형태소 분석기의 원리 - 1 (2) | 2024.12.23 |
|---|---|
| Real MySQL 8.0 읽기 - 아키텍처 (0) | 2023.07.21 |
| 슬로우 쿼리 모니터링 - AWS CloudWatch (0) | 2023.06.06 |
| DB Bulk Insert, Jmeter 부하테스트 (0) | 2023.06.06 |
| Lock을 이용한 동시성 제어 및 2PL(two phase locking) (0) | 2023.05.30 |


